Extract Clean Web Content with Anti-Bot Fallback for AI Agents & Workflows
This workflow contains community nodes that are only compatible with the self-hosted version of n8n. Clean Web Content Extraction with Anti-Bot Fallback Extract clean and structured text from any webpage with optional fallback to an anti-bot scraping service. Ideal for AI tools and content workflows. 🧠 How it Works This sub-workflow enables reliable and clean scraping of any public webpage by simply passing a url parameter. It is designed to be embedded into other workflows or used as a tool fo
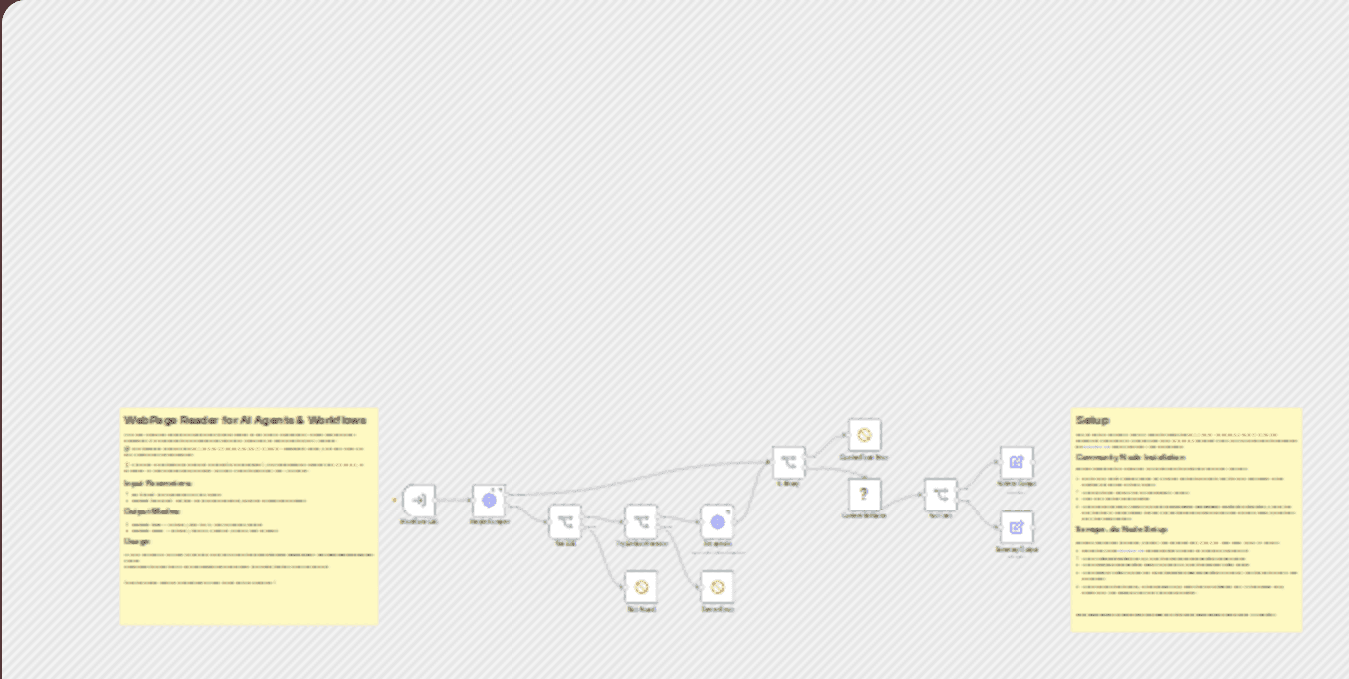
About this workflow
This workflow contains community nodes that are only compatible with the self-hosted version of n8n. Clean Web Content Extraction with Anti-Bot Fallback Extract clean and structured text from any webpage with optional fallback to an anti-bot scraping service. Ideal for AI tools and content workflows. 🧠 How it Works This sub-workflow enables reliable and clean scraping of any public webpage by simply passing a url parameter. It is designed to be embedded into other workflows or used as a tool for AI agents. It supports two output modes: - fulltext: true — returns { title, text } with full page content - fulltext: false — returns { title, url, content } with a short excerpt 💡 If the site is protected by anti-bot systems (like Cloudflare), it will automatically fallback to Scrape.do, a scraping API with a generous free plan. 🧩 This template requires the n8n-nodes-webpage-content-extractor community node, so it only works in self-hosted n8n environments. 🚀 Use Cases - As a reusable sub-workflow, via Execute Sub-workflow node. - As a tool for an AI Agent, compatible with Call n8n Workflow Tool. Perfect for chatbots, summarization workflows, or RSS/feed enrichment. Empowers your AI Agent with the ability to browse and extract readable content from websites automatically. 🔖 Parameters - url (string): the webpage URL to scrape - fulltext (boolean): set true for full page content, false for summarized output ⚙️ Setup - Install the community node n8n-nodes-webpage-content-extractor in your self-hosted n8n instance. - Create a free account at Scrape.do and obtain your API Token. - In the workflow, locate the Scrape.do HTTP Request node and configure the credentials using your API Token. - Detailed step-by-step instructions are available in the workflow notes. The Scrape.do API is only used as a fallback when conventional scraping fails, helping you preserve your API credits.
How to import this n8n workflow
- 1
Download the workflow JSON file after purchase.
- 2
Open n8n → click the menu → Import from File.
- 3
Select the downloaded JSON and import.
- 4
Set up credentials for each node that requires them.
- 5
Click Execute Workflow to test, then activate.
Setup guide
Setup guide included
Purchase to unlock the full step-by-step guide
Reviews
No reviews yet
Be the first to buy and share your experience.
Leave a review
Sign in to share your experience with this workflow.
Free
No ratings yet
Create a free account to purchase workflows.
- JSON blueprint — instant download
- Setup guide PDF included
- 5 downloads · valid 30 days
- Works with n8n
Free