Scrape Reddit posts with BrowserAct, summarize with Gemini, and save to Google Sheets
Google SheetsOpenAIGemini
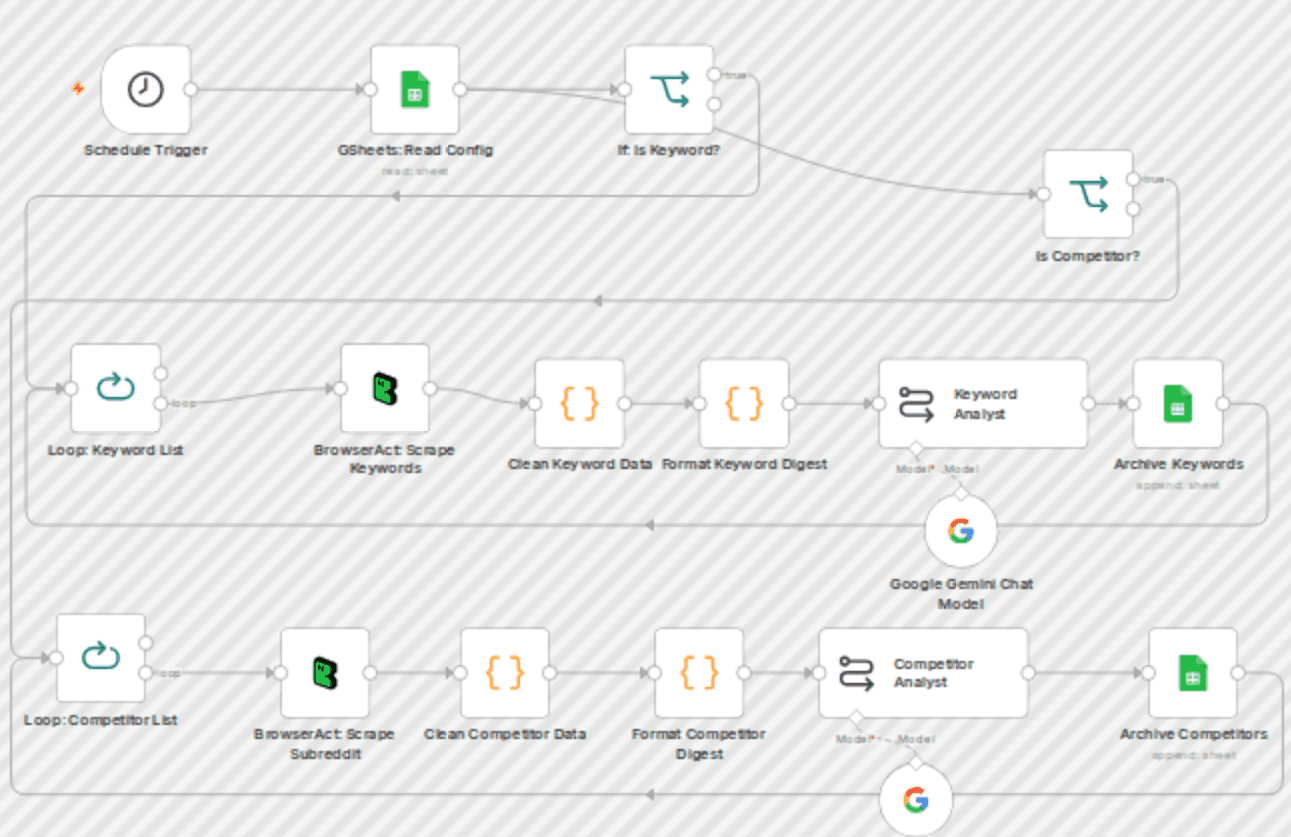
Reddit Intelligence Monitor: AI-Powered Scraping with BrowserAct Automate your market research and competitor analysis with this powerful "Set and Forget" workflow. It monitors Reddit for specific keywords and competitor subreddits, uses BrowserAct for stealth scraping, analyzes the sentiment with AI, and delivers a daily intelligence digest to your Google Sheets. 💡 Key Features - Powered by BrowserAct: Leverages cloud browser automation to stealthily scrape Reddit data with
About this workflow
Reddit Intelligence Monitor: AI-Powered Scraping with BrowserAct Automate your market research and competitor analysis with this powerful "Set and Forget" workflow. It monitors Reddit for specific keywords and competitor subreddits, uses BrowserAct for stealth scraping, analyzes the sentiment with AI, and delivers a daily intelligence digest to your Google Sheets. 💡 Key Features - Powered by BrowserAct: Leverages cloud browser automation to stealthily scrape Reddit data without getting blocked. - Dual-Track Monitoring: Simultaneously tracks "Brand Competitors" (Subreddits) and "Topic Keywords" (Search Results). - AI Analysis: Summarizes the top 3 trending posts into a single concise daily report, filtering out noise. - Structured Archive: Automatically cleans, formats, and archives intelligence with source links into Google Sheets. 🛠️ How it Works 1. Config Read: Reads a list of monitoring targets from a Google Sheet. 2. Route: Splits the task into two paths (Competitor vs. Keyword) based on input type. 3. Scrape: BrowserAct navigates to the target Reddit pages and extracts the latest posts. 4. Process: Custom Code nodes clean the data and merge top 3 posts into a single prompt. 5. Analyze: AI Agent generates an executive summary for each topic. 6. Archive: Final reports are appended to your "Report" Google Sheet. 📋 Setup Guide 1. Google Sheets: Create a sheet with two tabs: - Config: Columns keywords (for search terms) and competitor (for subreddit names). - Report: Columns Date, Competitor/Keyword, Summary, Link. 2. BrowserAct: Connect your BrowserAct credentials and ensure you have the Reddit scraping task template ready. 3. AI Model: Configure the Google Gemini Chat Model (or swap for OpenAI). 4. Schedule: Enable the Schedule Trigger for daily automated runs.
How to import this n8n workflow
- 1
Download the workflow JSON file after purchase.
- 2
Open n8n → click the menu → Import from File.
- 3
Select the downloaded JSON and import.
- 4
Set up credentials for each node that requires them.
- 5
Click Execute Workflow to test, then activate.
Setup guide
Setup guide included
Purchase to unlock the full step-by-step guide
Reviews
No reviews yet
Be the first to buy and share your experience.
Leave a review
Sign in to share your experience with this workflow.
Free
No ratings yet
Create a free account to purchase workflows.
- JSON blueprint — instant download
- Setup guide PDF included
- 5 downloads · valid 30 days
- Works with n8n
Free