AI-Powered Knowledge Base Builder — Turn Any Website into LLM-Optimized Markdown & TXT Files Automate the entire process of converting any website or domain into clean, structured, AI-ready knowledge bases for Large Language Models (LLMs), semantic search, and chatbot development. --- Key Workflow Highlights - URL Input via Simple Form – Paste a single link or a full domain. - Automated Link Discovery – Crawl and map all related pages with Firecrawl API. - Clean Markdown Extraction – Use Parsera
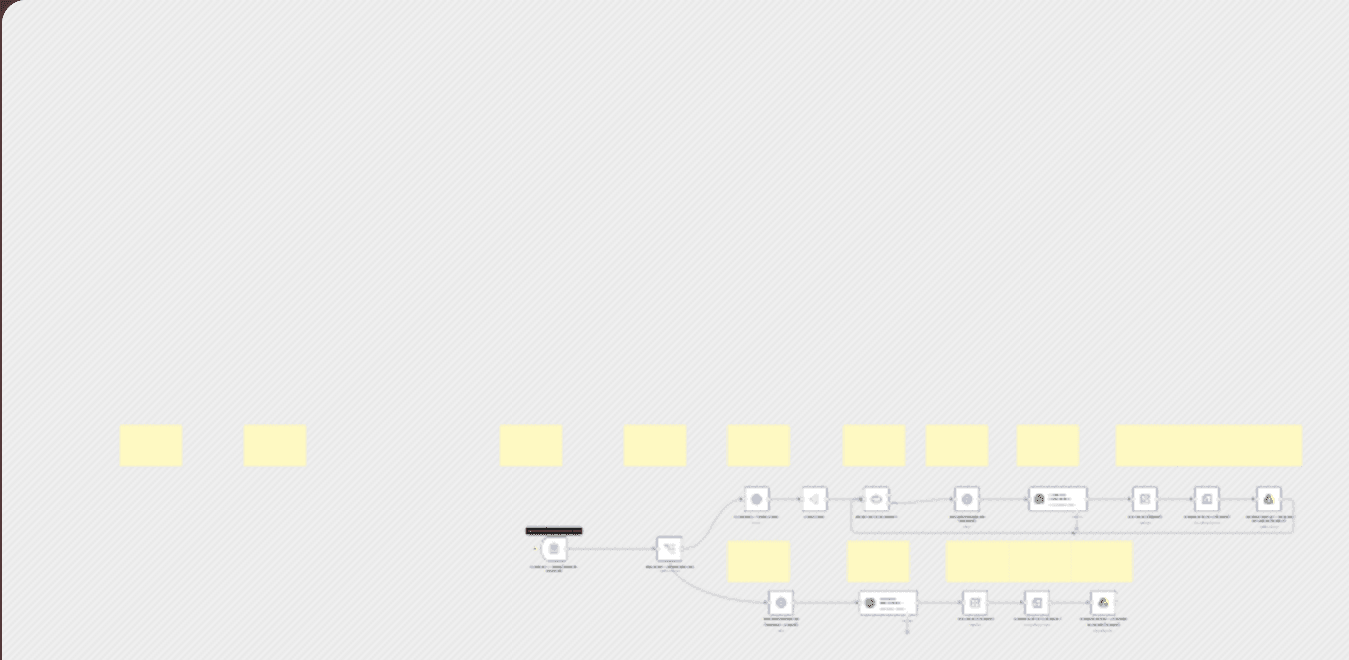
AI-Powered Knowledge Base Builder — Turn Any Website into LLM-Optimized Markdown & TXT Files Automate the entire process of converting any website or domain into clean, structured, AI-ready knowledge bases for Large Language Models (LLMs), semantic search, and chatbot development. --- Key Workflow Highlights - URL Input via Simple Form – Paste a single link or a full domain. - Automated Link Discovery – Crawl and map all related pages with Firecrawl API. - Clean Markdown Extraction – Use Parsera API for accurate, clutter-free content. - LLM-Optimized Formatting – Standardize with OpenAI GPT-4.1-mini for llms.txt. - Cloud Storage Integration – Save directly to Google Drive for instant access. - Batch Processing at Scale – Handle single pages or hundreds of URLs effortlessly. --- Perfect For: - AI engineers building domain-specific training datasets - Data scientists running semantic search & vector database pipelines - Researchers collecting website archives for AI or analytics - Automation specialists creating chatbot-ready content libraries --- Why This Workflow Outperforms Manual Processes - 100% Automated — From link input to Google Drive-ready .txt file - Flexible Scope — Choose between single-page extraction or full-site crawling - Clean, AI-Friendly Output — Markdown converted to standardized LLM format - Scalable & Reliable — Handles bulk data ingestion without formatting issues - Cloud-First — Centralized storage for team-wide accessibility --- Problems Solved - No more manual copy-paste from dozens of web pages - Eliminate formatting inconsistencies across datasets - Avoid scattered files — all output stored in one central folder Instead, you get: - Automated URL mapping for deep data coverage - Proxy-enabled scraping for accurate extraction - Ready-to-use llms.txt files for chatbots, fine-tuning, and AI pipelines --- How It Works — Step-by-Step 1. Form Submission Input your URL and choose “Single Page” or “Full Domain Crawl.” 2. URL Mapping with Firecrawl API Automatically discovers all internal links related to the starting URL. 3. Content Extraction with Parsera API Removes ads, navigation clutter, and irrelevant elements to produce clean Markdown. 4. LLM-Optimized Formatting with OpenAI GPT-4.1-mini Generates structured files including: - Site title & meta description - Page sections with summaries & full text 5. Cloud Upload to Google Drive Final .txt or .md files stored in your specified folder. --- Business & AI Advantages - Save 90%+ time preparing AI training datasets - Improve AI accuracy with high-quality, consistent input - Maintain centralized, cloud-based storage - Scale globally with proxy-based content collection --- Setup in Under 10 Minutes 1. Import the workflow into n8n. 2. Add credentials for: - Firecrawl API - Parsera API - OpenAI API Key - Google Drive (Service Account or OAuth) 3. Update your Google Drive folder ID. 4. Run a test job with a sample URL. 5. Deploy and connect to your AI pipeline. --- Tools & Integrations Used - n8n Form Trigger – For user-friendly input - Firecrawl API – Comprehensive internal link mapping - Parsera API – Clean, structured content extraction - OpenAI GPT-4.1-mini – LLM-optimized formatting - Google Drive API – Secure cloud storage - Batch & Switch Logic – Efficient multi-page processing --- Advanced Customization Options - Change output format: .md, .json, .csv - Swap storage to Dropbox, AWS S3, Notion, Airtable - Modify AI prompts for alternative formatting - Filter by keywords or metadata before saving - Automate runs via Google Sheets, email triggers, or cron schedules - Add AI-powered translation for multilingual datasets - Enrich with SEO metadata or author information - Push directly to vector databases like Pinecone, Weaviate, Qdrant --- SEO-Optimized Keywords for Maximum Reach - AI data extraction workflow - Automated LLM training dataset builder - Web to Markdown converter for AI - Firecrawl Parsera OpenAI n8n integration - llms.txt file generator for chatbots - Automated website content scraper for AI - Knowledge base creation automation - AI-ready data pipeline for semantic search - Batch website-to-dataset conversion
Download the workflow JSON file after purchase.
Open n8n → click the menu → Import from File.
Select the downloaded JSON and import.
Set up credentials for each node that requires them.
Click Execute Workflow to test, then activate.
Setup guide included
Purchase to unlock the full step-by-step guide
No reviews yet
Be the first to buy and share your experience.
Leave a review
Sign in to share your experience with this workflow.
Create a free account to purchase workflows.
Need help setting this up?
Book a 3-hour live setup session with an Agility consultant.