Triage incidents and enforce SLAs with Gemini, Groq, Google Sheets and Slack
GmailSlackGoogle SheetsGemini
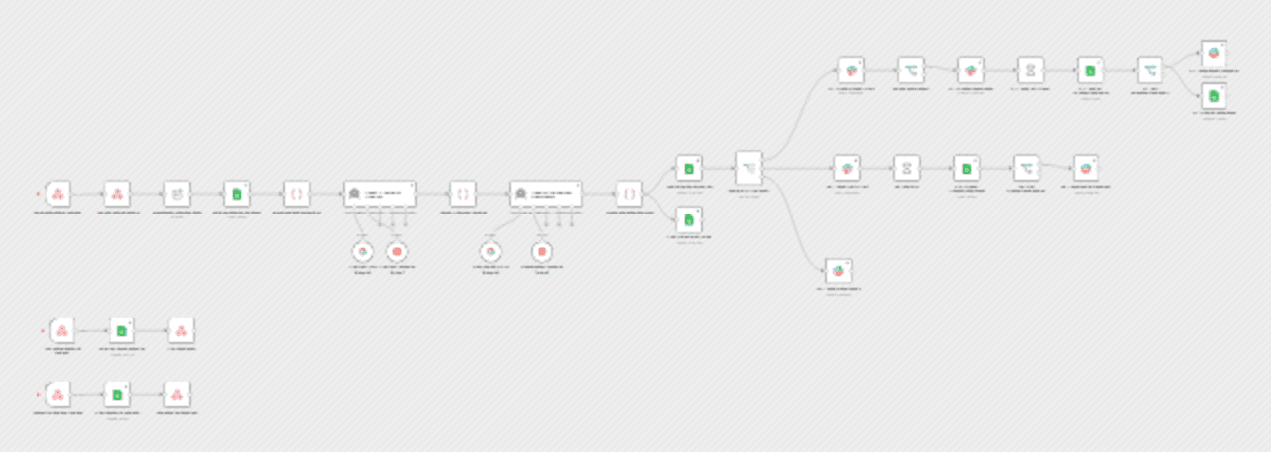
Reduce MTTR with context-aware AI severity analysis and automated SLA enforcement Know that feeling when a "low priority" ticket turns into a production fire? Or when your on-call rotation starts showing signs of serious burnout from alert overload? This workflow handles that problem. Two AI agents do the triage work—checking severity, validating against runbooks, triggering the right response. What This Workflow Does Incident comes in through webhook → two-agent analysis kicks off: Agent 1 (Inc
About this workflow
Reduce MTTR with context-aware AI severity analysis and automated SLA enforcement Know that feeling when a "low priority" ticket turns into a production fire? Or when your on-call rotation starts showing signs of serious burnout from alert overload? This workflow handles that problem. Two AI agents do the triage work—checking severity, validating against runbooks, triggering the right response. What This Workflow Does Incident comes in through webhook → two-agent analysis kicks off: Agent 1 (Incident Analyzer) checks the report against your Google Sheets runbook database. Looks for matching known issues, evaluates risk signals, assigns a confidence-scored severity (P1/P2/P3). Finally stops you from trusting "CRITICAL URGENT!!!" subject lines. Agent 2 (Response Planner) builds the action plan: what to do first, who needs to know, investigation steps, post-incident tasks. Like having your most experienced engineer review every single ticket. Then routing happens: - P1 incidents → PagerDuty goes off + war room gets created + 15-min SLA timer starts - P2 incidents → Gmail alert + you've got 1 hour to acknowledge - P3 incidents → Standard email notification Nobody responds in time? Auto-escalates to management. Everything logs to Google Sheets for the inevitable post-mortem. What Makes This Different | Feature | This Workflow | Typical AI Triage | |---------|--------------|-------------------| | Architecture | Two specialized agents (analyze + coordinate) | Single generic prompt | | Reliability | Multi-LLM fallback (Gemini → Groq) | Single model, fails if down | | SLA Enforcement | Auto-waits, checks, escalates autonomously | Sends alert, then done | | Learning | Feedback webhook improves accuracy over time | Static prompts forever | | Knowledge Source | Your runbooks (Google Sheets) | Generic templates | | War Room Creation | Automatic for P1 incidents | Manual | | Audit Trail | Every decision logged to Sheets | Often missing | How It Actually Works: Real Example Scenario: Your monitoring system detects database errors. Webhook receives this messy alert: Agent 1 (Incident Analyzer) reasoning: 1. Checks Google Sheets runbook → finds entry: "Connection pool exhaustion typically P2 if customer-facing" 2. Scans description for risk signals → detects "503 errors" = customer impact 3. Cross-references service name → confirms user-service is customer-facing 4. Decision: Override P3 → P2 (confidence score: 0.87) 5. Reasoning logged: "Customer-facing service returning errors, matches known high-impact pattern from runbook" Agent 2 (Response Coordinator) builds the plan: - Immediate actions: "Check active DB connections via monitoring dashboard, restart service if pool usage >90%, verify connection pool configuration" - Escalation tier: "team" (not manager-level yet) - SLA target: 60 minutes - War room needed: No (P2 doesn't require it) - Recommended assignee: "Database team" (pulled from runbook escalation contact) - Notification channels: #incidents (not #incidents-critical) What happens next (autonomously): 1. Slack alert posted to #incidents with full context 2. 60-minute SLA timer starts automatically 3. Workflow waits, then checks Google Sheets "Acknowledged By" column 4. If still empty after 60 min → escalates to #engineering-leads with "SLA BREACH" tag 5. Everything logged to both Incidents and AIAuditLog sheets Human feedback loop (optional but powerful): On-call engineer reviews the decision and submits: → This correction gets logged to AIAuditLog. Over time, Agent 1 learns which patterns justify severity overrides. Key Benefits - Stop manual triage: What took your on-call engineer 5-10 minutes now takes 3 seconds. Agent 1 checks the runbook, Agent 2 builds the response plan. - Severity validation = fewer false alarms: The workflow cross-checks reported severity against runbook patterns and risk signals. That "P1 URGENT" email from marketing? Gets downgraded to P3 automatically. - SLAs enforce themselves: P1 gets 15 minutes. P2 gets 60. Timers run autonomously. If nobody acknowledges, management gets paged. No more "I forgot to check Slack." - Uses YOUR runbooks, not generic templates: Agent 1 pulls context from your Google Sheets runbook database — known issues, escalation contacts, SLA targets. It knows your systems. - Multi-LLM fallback = 99.9% uptime: Primary: Gemini 2.0. Fallback: Groq. Each agent retries 3x with 5-sec intervals. Basically always works. - Self-improving feedback loop: Engineers can submit corrections via /incident-feedback webhook. The workflow logs every decision + human feedback to AIAuditLog. Track accuracy over time, identify patterns where AI needs tuning. - Complete audit trail: Every incident, every AI decision, every escalation — all in Google Sheets. Perfect for post-mortems and compliance. Required APIs & Credentials - Google Gemini API (main LLM, free tier is fine) - Groq API (backup LLM, also has free tier) - Google Sheets (stores runbooks and audit trail) - Gmail (handles P2/P3 notifications) - Slack OAuth2 API (creates war rooms) - PagerDuty (P1 alerts—optional, you can just use Slack/Gmail) Setup Complexity This is not a 5-minute setup. You'll need: Google Sheets structure: - 3 tabs: Runbooks, Incidents, AIAuditLog - Pre-populated runbook data (services, known issues, escalation contacts) Slack configuration: - 4 channels: #incidents-critical, #incidents, #management-escalation, #engineering-leads - Slack OAuth2 with bot permissions Estimated setup time: 30-45 minutes Quick start option: Begin with just Slack + Google Sheets. Add PagerDuty later. Who This Is For - DevOps engineers done being the human incident router - SRE teams drowning in alert fatigue - IT ops managers who need real accountability - Security analysts triaging at high volume - Platform engineers trying to automate the boring stuff
How to import this n8n workflow
- 1
Download the workflow JSON file after purchase.
- 2
Open n8n → click the menu → Import from File.
- 3
Select the downloaded JSON and import.
- 4
Set up credentials for each node that requires them.
- 5
Click Execute Workflow to test, then activate.
Setup guide
Setup guide included
Purchase to unlock the full step-by-step guide
Reviews
No reviews yet
Be the first to buy and share your experience.
Leave a review
Sign in to share your experience with this workflow.
Free
No ratings yet
Create a free account to purchase workflows.
- JSON blueprint — instant download
- Setup guide PDF included
- 5 downloads · valid 30 days
- Works with n8n
Free